OSS for the Semantic Web: Production Ready?

This is the story of how I tried to use Semantic Web technologies, like RDF and Linked Data, to achieve a basically simple task, and of everything that prevented me successfully doing so.
The Task
The very simple task (TM) was: Given the German Wikipedia identifier of an article (i.e. the part appearing in the browser address bar), like "Optimierung_(Mathematik)", get the dbpedia URI, in this case: http://dbpedia.org/resource/Optimization_%28mathematics%29.
This is a simple task, because we know how to do it "by hand": You would just open the Wikipedia article in a browser (where you could type ".../Optimierung_(Mathematik)" in the address bar) and then see the last part of the dbpedia URI in the link to the English Wikipedia entry. Append the urlencoded variant to "http://dbpedia.org/resource/" and you're done.
(This is not even always true; in this case, the title of the corresponding English Wikipedia article is "Mathematical optimization", but the dbpedia URI is http://dbpedia.org/resource/Optimization_%28mathematics%29.)
Language problems on dbpedia
Using dbpedia itself to retrieve this information is much harder, for a number of problems in the data:
The resource http://dbpedia.org/resource/Optimization_%28mathematics%29 itself has (a) no triple containing our given German identifier ("Optimierung_(Mathematik)"), neither (b) a link to the corresponding resource in the German dbpedia (
rdfs:label("Optimierung (Mathematik)").Actually, none of the dbpedia.org resources has (b) a link to its counterpart on de.dbpedia.org (the same is true the other way around, this seems to be a design decision). As far as (c)
rdfs:label@deis concerned, many resources carry the correct German label in that attribute, but most (really, "most"!) resources on dbpedia.org (like dbpedia:Berlin) don't (FAIL), while many other languages are present.Maybe this is related to the German N3 dump in the dbpedia.org download area being broken, in the sense of abruptly ending in the middle of some arbitrary tuple (BIG FAIL). A corrected version of the downloads is available, but the endpoint won't be updated until the next dbpedia release.
The German dbpedia at http://de.dbpedia.org does not handle special characters like Umlauts correctly (FAIL). For example, while http://de.dbpedia.org/page/Dodekaeder lists
<http://de.dbpedia.org/resource/Dodekaeder> dbpedia-owl:wikiPageWikiLink <http://de.dbpedia.org/resource/Platonischer_K%C3%B6rper>as a triple, accessing http://de.dbpedia.org/resource/Platonischer_K%C3%B6rper results in HTTP 404.
Strategy
As I expected the bugs concerning the German labels at dbpedia.org and the Umlaut problem at de.dbpedia.org to be fixed in finite time (but not the missing links between them), I decided on the following procedure:
Get the
rdfs:labelof the de.dbpedia.org resource with foaf:page"http://de.wikipedia.org/wiki/" + urlencode($term). (We could also handle$terms that are names of a Wikipedia redirect, as there is a propertydbpedia-owl:wikiPageRedirectsstored with the corresponding dbpedia resources.)Get the dbpedia.org resource with rdfs:label
"$label"@de.
Accessing the necessary datasets
While it seems common practice to just load the N3 dumps into your local triple store, I didn't want to go down this road, as I
would need to provide storage (dbpedia is huge!), CPU time and software infrastructure myself and
would have to upgrade to recent datasets regularly myself.
Now there are two possibilities to access different remote endpoints from your application. Either (a) connect to each endpoint (in this case, http://dbpedia.org/sparql and http://de.dbpedia.org/sparql) separately and ask the queries there, or (b) issue a federated SPARQL query against one endpoint that will in turn get the results from nested queries from other endpoints. Such a query could look like:
SELECT * WHERE {
SERVICE <http://dbpedia.org/sparql/>
{
SELECT ?res WHERE {
?res <http://www.w3.org/2000/01/rdf-schema#label> "Mathematik"@de .
}
}
SERVICE <http://de.dbpedia.org/sparql/>
{
SELECT ?res_de WHERE {
?res_de <http://www.w3.org/2000/01/rdf-schema#label> "Mathematik"@de .
}
}
}
If the http://www.w3.org/2000/01/rdf-schema# is pulled out as a PREFIX, this leads to a crash of the sparql-query command line tool. (Not sure who is responsible, maybe it's the endpoint's fault, but FAIL anyway.) The result of the above query is something like:
| ?res | ?res_de |
| <http://dbpedia.org/resource/Mathematics> | <http://de.dbpedia.org/resource/Mathematik> |
| <http://dbpedia.org/resource/Mathematics> | <http://de.dbpedia.org/resource/Kategorie:Mathematik> |
In Pseudo-SQL, this query would be equivalent to something like SELECT * FROM (SELECT res FROM <http://dbpedia.org/sparql/> WHERE rdfs:label = 'Mathematik') CROSS JOIN (SELECT res_de FROM <http://de.dbpedia.org/sparql/> WHERE rdfs:label = 'Mathematik');
Having just one endpoint to query instead of many is a good thing because (a) you can use information from one triple store in your queries against another and (b) you can easily put an HTTP cache in front of that one endpoint (like nginx). However, two problems arise in this case:
SPARQL endpoints on the web will usually not allow federated SPARQL queries, as it is too easy to (also without purpose) pull massive amounts of data through them.
Not too many implementations already support federated queries. From what I can remember, the ARQ library to parse SPARQL queries (which is used by the SPARQL endpoint implementations Joseki and Fuseki) was the only one I could find out about that does so.
Setting up Joseki
This is described in another blog post.
Note that Joseki sets the Cache-Control HTTP header to no-cache (WHY?), so you need to set
proxy_ignore_headers Cache-Control;
in nginx's configuration file (or whatever caching server you want to use).
Querying your local endpoint
Say the Joseki endpoint is http://localhost:8080/joseki/sparql (without a trailing slash; other endpoints, like 4store require it), then you can now start querying the endpoint with (federated) queries, but of course only with those, as there are no other triples stored with Joseki so far. To do so, there are a number of libraries, but a good (because simple) command line application is sparql-query (hard to google that tool, though) that feels just like a familiar SQL client:
$ ./sparql-query http://localhost:8080/joseki/sparql
sparql$ SELECT ?s ?p ?o WHERE { ?s ?p "Optimierung (Mathematik)"@de };
┌────┬────┬────┐
│ ?s │ ?p │ ?o │
├────┼────┼────┤
└────┴────┴────┘
sparql$ SELECT ?lbl_de WHERE {
SERVICE <http://dbpedia.org/sparql/> {
SELECT ?lbl_de WHERE {
<http://dbpedia.org/resource/Geometry> <http://www.w3.org/2000/01/rdf-schema#label> ?lbl_de .
FILTER(LANG(?lbl_de) = "de")
}
}
};
┌───────────┐
│ ?lbl_de │
├───────────┤
│ Geometrie │
└───────────┘
Unfortunately, you will have to compile sparql-query yourself, but except for installing the missing dev libraries, it's hard to make mistakes here.
To query the endpoint from a PHP script, there's ARC2 and RAP. While ARC2 seems more up-to-date, it is more centered towards accessing a local triple store than to send queries to remote endpoints. It supports that as well, but parses the SPARQL query beforehand and fails at the SERVICE keyword (FAIL), i.e. it cannot be used for federated SPARQL queries.
RAP just sends the raw query via plain HTTP 1.0 (it will fail with 1.1 responses because it does not understand chunked encoding) to the endpoint, i.e. it does not do any syntax checks etc. beforehand and leaves this to the endpoint. In particular, it is well suited to issue federated queries. However, when querying Joseki using RAP, the built-in Accept header with value application/sparql-results+xml, application/rdf+xml does not lead to a result in a format that RAP's SparqlClient can handle (FAIL). Thus, I subclassed the SparqlClient with a class called JsonSparqlClient that sends Accept: application/sparql-results+json instead and jsondecodes the reply.
Working around dbpedia's language problems
Now we've got a working setup to query the world with federated SPARQL queries. The problems about missing German labels in the dbpedia described above still remain and need to be worked around. Thus, I decided to load the (repaired) dbpedia dumps of German labels into a local store, at least until dbpedia.org uses the fixed dataset as well.
The best solution, it seems, would be to store that data in a TDB triple store that is embedded in the local Joseki endpoint. The two alternatives to load triple data into TDB are to use (a) the SPARQL Update protocol or (b) command line tools to directly manipulate the TDB store. Trying to go down the first road, I did not find a tool that was able to communicate my SPARQL Update requests to the Joseki store successfully (where I'm not exactly sure, whose fault that is). To directly manipulate the TDB store, a number of command line applications come with the TDB distribution. However, there seems to be some issue with locking-for-write that makes the data inserted this way inaccessible for the running Joseki server. As I found no feasible way to load and edit the triple data in this setup, I had to think of something else.
On the same machine, I installed another triple store with integrated SPARQL endpoint, namely 4store. It needs some work to build and install the latest version on a rather old Ubuntu system, but the reward is a fast and stable triple store with a number of great command line tools, like 4s-import, 4s-update, 4s-query, or 4s-dump, that I was missing in the Joseki distribution (or an appropriate documentation). I imported the German label dump from dbpedia and now use federated queries against dbpedia.org, de.dbpedia.org, and my local 4store endpoint to get the information I want.
Conclusion
Phew, this was a long way. The whole setup now looks as follows:
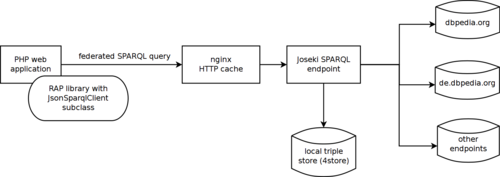
I arrived at a setup that does what I wanted, but I feel that for this particular case, querying the Wikipedia API would have been a lot easier. Anyway, I'm happy that I got this setup working, because
- in the future, I can easily pull in information from arbitrary SPARQL endpoints and use it in my web application,
- I still perform well through the nginx cache in between, and
- I can store additional information in a local triple store.
A major problem was that large parts of the available software often lack completeness and robustness. In parts, this is due to evolving standards (like SPARQL Update or SPARQL Federated Queries); but also it is often the case that some software was started as a research project, but never got to a usable state or is just not maintained any more. However, quite a bunch of information that you might want to use in your application is just not available by other means, see the Use Cases on dbpedia.org. So I think that in the end, investing the time to dig into this whole "Linked data stuff" might finally turn out as a good idea.